
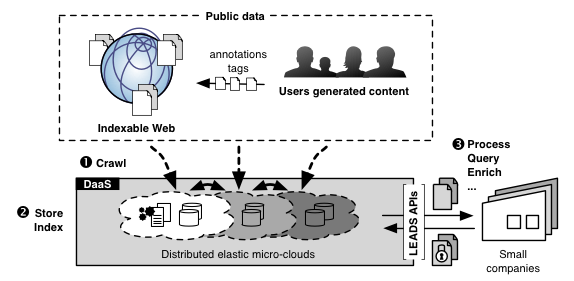
The objective of LEADS was to investigate a novel approach for (Big)-Data-as-a-Service, such that the real-time processing of private and public data becomes economically and technically feasible even for small and medium-sized enterprises, or for larger companies that do not wish to perform these operations in house. In order to reach its goal, LEADS developed a complete architecture with means to (1) gather and (2) store publicly available data, and provides a platform for (3) processing this data in real time. This page presents the main realization of the project. You might want to check the news section of this site, our list of issued software and our stream of scientific publications, for more details. If you need more information, do not hesitate to get in touch with the project members.
Our objectives
Our design is intended to fulfill several functional requirements. For collecting offline data, we developed an efficient and timely web crawler. For online data collection, an interface (built as a Chrome plugin) allows to attach user generated metadata to the public data and to direct the crawling operation. For storage, we offer the possibility to maintain historical versions of data element stored, and support user-defined specific functions in the form of plugins, allowing pre-processing and filtering of data right upon its collection, for an efficient and minimal-cost querying later. Querying can either use traditional one-shot queries (in the form of MapReduce or SQL queries) and stream-oriented queries (using CQL). Queries can be expressed in high-level declarative languages but we also offer a simple graphical interface for non-experts. Our project features a representative application built by partner adidas, that exploits the wealth of publicly available web data to gather and query business-specific information as easily as it would be to process a locally store document base.
In addition to its service model, the project proposes advances on the non-functional front as well. We expect to minimise the environmental impact of the platform by using multiple micro-clouds. By exploring cogeneration in the micro-clouds, we reuse computing dissipation, otherwise lost in the environment, as household heating. We produce a dependable data grid by extensively replicating data across micro-clouds. The platform is also flexible thanks to its rich querying capabilities. Last but not least, LEADS software is efficient, thanks to its smart replication and scheduling algorithms, that preserve locality in order to reduce the number of transfers through the Internet.
Our realizations
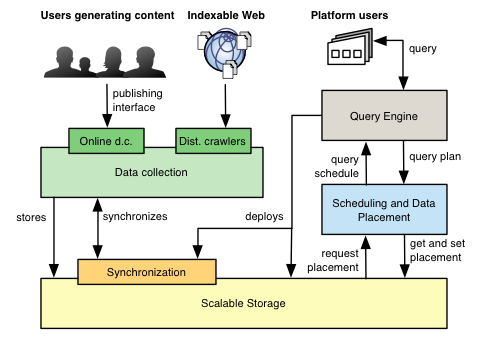
Together, the realizations listed on this page form the LEADS platform, a proof-of-concept service platform aiming at demonstrating the possibility of building (Big-)Data-as-a-Service and supporting it on a sustainable decentralized cloud infrastructure.
Data Collection
We built a geo-distributed crawler system named UniCrawl and available on GitHub. UniCrawl supports crawling efficiently from multiple sites. Each site operates using an independent crawler (open source Apache Nutch) and relies on well-established techniques for fetching and parsing the content of the web. UniCrawl splits the crawled domain space across multiple sites and federates their storage and computing resources, while minimizing the inter-site communication cost. We validated UniCrawl through a deployment in multiple cities in Germany including Dresden, Hamburg and Münster.
In addition to crawling, the LEADS platform allows users to enrich public data with user generated data such as tags or comments, and to specify to the crawler a particular page to fetch in order to speed up the discovery of important to the user, but less connected, pages. This support takes the form of a browser plugin for the Chrome browser. Our experiments show that the user-aided data collection enables to collect the data that is difficult to collect with the crawling-based data collection mechanism. This component is not open source for the moment; please get in touch if you want more information about it.
Similarly to the traditional crawling systems, it is important to have a solid spam detection mechanism to filter out anomalous data. The mechanism to implement a spam detector is to collect users and content data, pass it through a complex machine learning model (i.e. a model that is intelligent enough to learn from the data, without being explicitly programmed for the particular task) and to come up with a “content spam score”. Clean data coming from user behavior motivated us to perform new research on how to update the crawled data. As Internet is a dynamic reality, the crawled web pages can become obsolete after a while. We built an estimator of web page importance and decide on the next pages to refresh based on users collected data. The model relies on user behavior features and a complex machine learning model to learn from the data called GBDT (Gradient Boosting Decision Tree). Experiments have shown the effectiveness of our spam detectors model, which can reach high accuracy, and we also presented results on how to use this data from efficiently refresh crawled web pages.
Scalable Storage
We developed a scalable, multi-site storage layer with enriched data processing capabilities, support for multi-site synchronization, and more. All our contributions on that front are open source and listed at the end of this page. We contributed in particular to Infinispan a highly available, in-memory, key-value store.
The storage layer of LEADS is called Ensemble. It aggregates multiple, independent storage clusters on different sites (micro-clouds) and provides the vision of a massive, robust and energy-efficient storage layer. In order to maximize locality and performance, data is explicitly placed across sites. Data can be replicated across sites, and consistency levels can be tuned in a fine-grain manner between immutable, eventual or strong. Ensemble is available on GitHub.
The LEADS storage layer offers a rich storage interface that supports data versioning, abstract data types, stream processing and collections. Versioning allows for historic queries on data and for establishing consistent cuts on web graphs. Abstract data types allow for synchronized partial operations in larger data structures as queues or maps. The stream processing interface allows for forwarding selected data updates directly to an external component and is used by our Plugins to support part of the query engine. Filtered collections can also be built as the updates happen, allowing to prefilter data for subsequent one-shot queries.
One important outcome of our work on the storage layer is the Atomic Object Factory, that allows storing and sharing Java objects that are automatically replicated and maintained consistent. This work has been integrated in Infinispan and is based on a novel distributed construct allowing a scalable implementation of State Machine Replication.
Finally, we also provide support for multi-site coordination through the ZooFence library. This library allows coordinating instances of the Apache ZooKeeper open source coordination kernel. ZooFence employs partitioning techniques to maximize locality and performance in a multi-site setting. ZooFence is available on GitHub.
Query Engine
The querying requirements of LEADS users are supported by a widely distributed query execution engine that exploits the scalable storage capabilities of the LEADS Ensemble and the massive computing infrastructure enabled by the combination of micro-clouds. The engine supports data organization in relational format (with fixed-schema tables and indexes), but in addition enables unbounded-size string attributes, which are critical in some contexts, e.g., storing of arbitrary web content. Users interact in two ways with the engine: (a) through a mashup-based graphical interface, which is typically sufficient for inexperienced users and (b) through a command-line interface and an API for executing queries expressed via SQL, the most widespread declarative language for querying. The relational operators are implemented over MapReduce to utilize the processing capabilities of the distributed nodes.
Arbitrary data processing is offered to the user via two approaches: (a) a novel plugin architecture, which enables on-the-fly (streaming) processing of all updates committed in Ensemble, and (b) a novel multi-cloud MapReduce execution engine. The plugin architecture supports near-real-time processing of incoming data (fetched by UniCrawl) for the specific needs of a client. For instance, a SME might need to filter and pre-process new pages when they contain its name or that of a competitor, product, etc.; the follow-up one-shot query can only use the small, always up-to-date data set resulting from this operation. Plugins are built on top of the storage layer event mechanism, itself based on HotRod Remote Events. The mechanism allows to catch all updates in the KVS and to process them with arbitrary user-provided code. Due to the inherent distribution of the data, plugins are also executed in a distributed fashion, promoting scalability. Such plugins are already constructed, both in the context of WP3 to support efficient indexing and collection of statistics for the query planner, but also by the end-user for satisfying application-specific processing requirements. In terms of processing of stored data, our multi-cloud MapReduce enables batch distributed processing over all data stored in the Ensemble. The engine is optimized so that each data is processed locally, and small messages between micro-clouds are batched together to avoid heavy network congestion.
Utilizing the query engine and the data processing capabilities of LEADS, we have shown how to address frequent algorithmic problems over distributed settings. For example, we have proposed and integrated in LEADS a stochastic continuous PageRank maintenance algorithm that scales well over multi-cloud (shared-nothing) architectures. The algorithm is implemented as a plugin. We have also shown how to safely store private data in the LEADS infrastructure and how to execute range queries over them. This functionality is integrated in LEADS query engine, and is accessible to the developers via an API. Finally, we have shown how to maintain the top-k frequent items (ECM-sketches and TOPiCo), and how to track complex skylines over fast widely-distributed streams. Similar to PageRank, these works for top-k tracking can be easily integrated in LEADS as plugins.
Finally, we considered various problems and solutions related to the query engine such as query authentication, sketch-based queries and efficient stream analysis.
Scheduling and Data Placement
Scheduling is performed at two different levels in LEADS: virtual machines and query components. Scheduling VMs is done by selecting a preferred micro-cloud for running computations. We base the selection on needs for heating, on the availability of green energy, and on resource availability. Query component scheduling is based on data availability, using replica location information from the storage layer. Queries are mapped on to virtual machines that minimize remote access.
Data placement decides on the scope (key ranges) and the placement of caches. It is triggered upon creation of new caches (or upon repair after a failure). It keeps private and temporary data close to the data sources and splits public data based on a dictionary (inversed URLs).
In order to map virtual machines to micro clouds, we developed a cost-based scheduler that utilizes annotations provided by the query graph that expresses the cost of each operator and the approximate output volume in concert with traffic and computation costs of each micro cloud. The scheduler has been carried out using neural networks which are first trained using genetic algorithms and then used for taking scheduling decisions. The experimental evaluation reveals that the approach clearly outperforms a random placement of VMs.
Demonstrator
We built a demonstrator to assess the viability of the LEADS approach for a non-IT company willing to extract, process and query large amounts of public Web data. This demonstrator, led by partner adidas who plays the role of the end user in the project, collects information about assets of interests, and the context of these mentions using a set of data mining and data profiling techniques. The processing of collected data is performed by specific plugins, and allows efficient and fast queries when used by the market specialists targeted by the application. We were able to run this test application with a crawl of billion webpages on an infrastructure formed by 3 micro-clouds and get significative results.
