Summary: The LEADS project (2012-2015) has built a cloud service platform for Big Data as a Service. The project demonstrated that the benefits of Big Data and large-scale computing could be democratized enough to be usable by SMEs and non-IT-focused companies. It achieved this goal by building a proof-of-concept platform that allows non-specialist users to crawl, process, store and analyze vast amount of public and private Web data. Furthermore, it has shown that such a platform can run on an energy-efficient, local and sustainable infrastructure formed of a collection of tiny data centers, which we call micro-clouds.
The LEADS contributions are available as Open Source on the project GitHub page.
See also our software page for a detailed list of our open source contributions..
Our goals and achievements
LEADS was a research project funded by the European Commission under the FP7. It started in October 2012 and ended in September 2015. Three universities and four companies teamed up to build and demonstrate a novel cloud service model named (Big-)Data-as-a-Service, on top of an innovative infrastructure based on multiple energy-conscious micro-clouds.
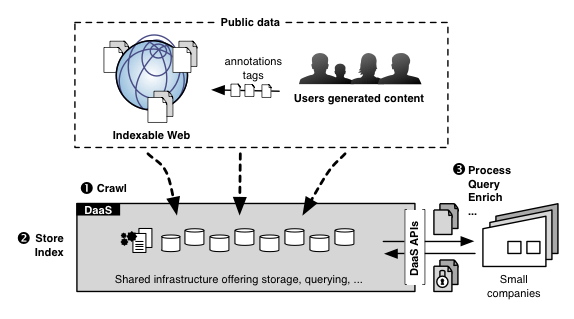
LEADS worked on answering the demand of companies wishing to exploit the wealth of public data available on today's Internet. Large IT-oriented companies can already crawl, store, and query large amounts of data in their own premises, giving them a key advantage. But small companies (SMEs) and companies that are not primarily on the Internet analytics business are also interested in taking advantage of Big Data. For instance, they may want to:
- Analyze the Web graph to extract business intelligence based on their business specific needs;
- Match some company-specific private data to a large quantity of public data;
- Monitor in real-time public data evolution and detect trends, identify opinion leaders, etc.;
- Propose novel data-enabled services such as complex graph analytics or real-time data aggregation.
Unfortunately, SMEs and non-IT companies were not be able or willing to crawl, store and process vast amount of public data in-house, because of the associated high cost, complexity, or simply because they miss the necessary expertise. Can these companies rely on larger ones for accessing and processing public content? Querying capabilities, and data freshness and comprehensiveness would depend on the provider's good will. Also, there are little guarantees on confidentiality. Data is power, and power is seldom willingly shared.
The LEADS research initiative demonstrated that a novel (Big-)Data-as-a-Service solution is viable to answer the need for small actors willing to take advantage of Big Data. Our proof-of-concept platform mutualizes the costs of extracting, storing and processing public data, while offering rich and extensible possibilities, including the ability to register near-real-time processing on newly-fetched data, the ability to query data efficiently across multiple sites, and more.